Лабораторная работа №1
Методы сортировки
1. Цель работы
Цель данной работы:
- изучить различные методы сортировки;
- научиться проводить сравнительный анализ методов друг с другом и выбирать наиболее подходящий для конкретных целей алгоритм сортировки.
2. Краткие сведения из теории
2.1. Значимость и суть задачи
Данный раздел посвящен сортировке: назначению, различным методам, их сравнительному анализу.
Сортировка - это процесс упорядочения некоторого множества элементов, на котором определены отношения порядка >, <, і , Ј . Когда говорят о сортировке, подразумевают упорядочение множества элементов по возрастанию или убыванию. Рассмотрим различные алгоритмы сортировки и выясним, почему возникла необходимость появления такого большого числа алгоритмов решения одной и той же задачи.
Вообще, алгоритмы сортировки - одна из самых хорошо исследованных областей информатики. Тем не менее не исключены открытия и в этой области, потому что наверняка существуют еще какие-то пока неизвестные методы сортировки, основанные на новых принципах и идеях.
Алгоритмы сортировки имеют большое практическое применение. Их можно встретить почти везде, где речь идет об обработке и хранении больших объемов информации. Некоторые задачи обработки данных решаются проще, если данные упорядочены. Примеры таких задач мы рассмотрим в этой лабораторной работе.
Интересным моментом в исследовании этой задачи является то, что переход от тривиальных алгоритмов к базирующимся на тех же принципах алгоритмам повышенной эффективности (от простого включения к методу Шелла; от простого извлечения к древесной сортировке; от пузырьковой сортировки к быстрой) требует значительного «концептуального прыжка». В таких случаях менее интересен поиск «микроскопических» улучшений, дающих экономию нескольких тактов процессора, чем занимаются многие программирующие на ассемблере.
2.2. Методы сортировки
Традиционно различают внутреннюю сортировку, в которой предполагается, что данные находятся в оперативной памяти, и важно оптимизировать число действий программы (для методов, основанных на сравнении, число сравнений, обменов элементов и пр.), и внешнюю, в которой данные хранятся на внешнем устройстве с медленным доступом (магнитные лента, барабан, диск) и прежде всего надо снизить число обращений к этому устройству.
В этой работе рассмотрим алгоритмы внутренней сортировки массивов элементов, так как они более важны большинству программистов в повседневной практике.
Стоит заметить, что алгоритм сортировки слиянием удобно применять и при сортировке внешних данных. При этом речь будет идти о слиянии файлов.
2.2.1. О сложности алгоритмов
При рассмотрении методов будем оперировать понятиями временной T и пространственной O теоретической сложности (в дальнейшем будем опускать слово «теоретическая») алгоритма, поэтому вкратце упомянем, что это такое.
Сложность алгоритма - одночлен, отражающий порядок величины требуемого ресурса (времени/дополнительной памяти) в зависимости от размерности задачи.
Например, если число тактов (действий), необходимое для работы метода, выражается как 11*n2+19*n*log(n)+3*n+4, где n-размерность задачи, то мы имеем дело с алгоритмом со сложностью T(n2). Фактически, мы из всех слагаемых оставляем только слагаемое, вносящее наибольший вклад при больших n (в этом случае остальными слагаемыми можно пренебречь) и игнорируем коэффициент перед ним.
В большинстве случаев оказывается довольно трудно найти точную практическую сложность алгоритма (функцию от n, позволяющую точно определить требуемое время работы/объем памяти). Однако, теоретическую сложность найти можно и это достаточно просто.
Временная (пространственная) сложность не позволяет определить время (необходимый объем дополнительной памяти) работы алгоритма, но она позволяет оценить динамику роста времени (объема дополнительной памяти), необходимого для работы метода, при увеличении размерности задачи. Например, для алгоритма с временной сложностью T(n2) при достаточно больших n можно утверждать, что при увеличении размера задачи (при сортировке - размера массива) в 3 раза время работы алгоритма увеличится в 32=9 раз.
Если операция выполняется за фиксированное число шагов, не зависящее от размера задачи, то принято писать T(1).
Надо помнить, что перед одночленом, отражающим сложность, стоит некоторый коэффициент C. Поэтому алгоритмы с одинаковой сложностью могут сильно отличаться временем исполнения.
Практически время выполнения алгоритма зависит не только от объема множества данных (размера задачи), но и от их значений, например, время работы некоторых алгоритмов сортировки значительно сокращается, если первоначально данные частично упорядочены, тогда как другие методы оказываются нечувствительными к этому свойству. Чтобы учитывать этот факт, полностью сохраняя при этом возможность анализировать алгоритмы независимо от данных, различают:
- максимальную сложность , или сложность наиболее неблагоприятного случая, когда метод работает дольше всего;
- среднюю сложность - сложность метода в среднем;
- минимальную сложность - сложность в наиболее благоприятном случае, когда метод справляется быстрее всего.
Алгоритмы, рассматриваемые здесь, имеют временные сложности T(n2), T(n*log(n)), T(n). Минимальная сложность всякого алгоритма сортировки не может быть меньше T(n). Максимальная сложность метода, оперирующего сравнениями, не может быть меньше T(n*log(n)). Доказательство последнего факта можно найти в многочисленной серьезной теоретической литературе, посвященной проблемам сортировки. Однако есть методы, которые не сравнивают элементы между собой. Мы рассмотрим один из них - сортировку распределением.
Для дальнейшего изложения нам понадобится следующее тождество:
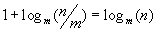 , nі m
, nі m
Доказательство:
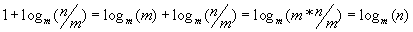
Посмотрим, как получаются сложности, с которыми нам придется столкнутся при выполнении лабораторных работ этого учебного пособия. Рассмотрим их в порядке возрастания.
- Сложность T(log(n)).
Из всех рассматриваемых здесь сложностей эта самая малая. Действительно, при достаточно большом n: log(n)<n<n*log(n)<n2.
Эта сложность получается, если на каждом шаге метода выполняется некоторое постоянное число действий C и задача размерности n сводится к аналогичной задаче размерностью n/m, где m – целая положительная константа:
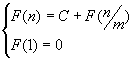 Þ
Þ 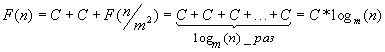
Доказательство:
(При доказательстве этой и нижеследующих формул сложности используется метод математической индукции)
- F (1)=С*logm(1)=0;
- Пусть
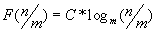
Тогда 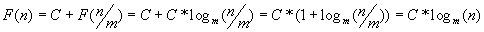 , что и требовалось доказать.
, что и требовалось доказать.
Примеры методов с такой сложностью вы можете найти в лабораторных работах по темам «Методы поиска», «Управление сбалансированными деревьями», «Управление b-деревьями».
- Сложность T(n).
Такая сложность получается в обычных итерационных процессах, когда на каждом шаге метода задача размерности n сводится к задаче размерности n-1, и при этом на каждом шаге выполняется некоторое постоянное число действий C, не зависящее от n:
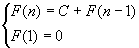 Þ F(n)=C*(n-1)=C*n-C
Þ F(n)=C*(n-1)=C*n-C
Доказательство:
- F(1)=С*(n-1)=0;
- Пусть F(n-1)=C*(n-2)
Тогда F(n)=C+F(n-1)=C+C*(n-2)=C*(1+n-2)=C*(n-1), что и требовалось доказать.
Примером такой сложности может служит любой цикл, в котором число итераций прямо зависит от n. В этой работе такие методы можно найти при рассмотрении лабораторной работы по теме «Методы поиска». Также некоторые методы сортировки в лучшем случае (если массив уже отсортирован) выполняют порядка n действий, а сортировка распределением всегда требует порядка n действий.
- Сложность T(n*log(n)).
Эта сложность получается, если на каждом шаге метода выполняется некоторое количество действий C*n, то есть зависящее от размера задачи прямопропорционально, и задача размерности n сводится к задаче размерностью n/m, где m – целая положительная константа:
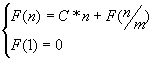 Þ F(n)=C’*n*logm(n)
Þ F(n)=C’*n*logm(n)
Доказательство:
- F(1)=С*logm(1)=0;
- Пусть
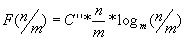
Тогда 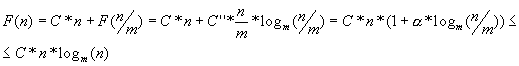 (0<a <1), что и требовалось доказать.
(0<a <1), что и требовалось доказать.
Примеры алгоритмов с такой сложностью можно найти в лабораторной работе, посвященной сортировкам.
- Сложность T(n2).
Такая сложность получается, когда мы имеем два вложенных цикла, число итераций которых зависит от n прямопропорционально. Или другими словами, на каждом шаге метода задача размерности n сводится к задаче размерности n-1, и при этом выполняется некоторое количество действий C*n, то есть зависящее от n прямо пропорционально:
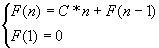 Þ F(n)=C’*n2+C’’
Þ F(n)=C’*n2+C’’
Доказательство:
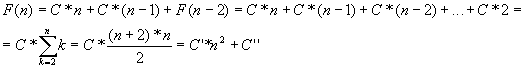 , что и требовалось доказать.
, что и требовалось доказать.
Примеры алгоритмов с квадратичной сложностью вы можете найти в лабораторной работе по теме «Методы сортировки». Это все простые и малоэффективные при больших n методы сортировок (в том числе получившая широкую известность благодаря рассмотрению во многих школьных учебниках информатики пузырьковая сортировка).
При рассмотрении алгоритмов сортировки прежде всего нас будет интересовать максимальная и средняя сложности метода, так как именно они, как правило, важны на практике. Максимальная сложность показывает поведение алгоритма в худшем случае, а средняя сложность – наиболее вероятное поведение при увеличении размера сортируемого массива. Сводные данные о сложности рассматриваемых методов можно найти в приложении 2 в конце работы.
Начнем разбор алгоритмов.
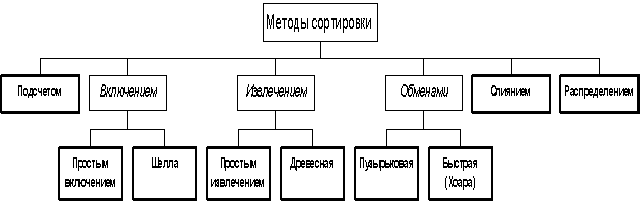
2.2.2. Сортировка подсчетом
Суть метода заключается в том, что на каждом шаге мы подсчитываем, в какую позицию результирующего массива надо записать очередной элемент исходного массива. Выглядит это так:
for i := 1 to N do
begin
<вычислить_место_k+1_элемента_A[i]
в_результирующем_массиве_B>
B[k+1] := A[i];
end;
Слева от B[k+1] должны стоять элементы большие или равные B[k+1]. Значит число k складывается из количества элементов меньших A[i] и, возможно, некоторого числа элементов, равных A[i]. Условимся, что из равных мы будем учитывать только те элементы, которые в исходном массиве стоят левее A[i]. Теперь вычисление k можно записать следующим образом:
k := 0;
for j := 1 to N do
if (A[i]>A[j])or((A[i]=A[j])and(i>j)) then
Inc(k);
Легко видеть, что этот алгоритм всегда имеет сложности T(n2) (два вложенных цикла, зависящих от n линейно) и O(n) (результирующий массив).
2.2.3. Сортировка включением
В этой сортировке массив делится на 2 части: отсортированную и неотсортированную. На каждом шаге берется очередной элемент из неотсортированной части и «включается» в отсортированную часть массива.
2.2.3.1. Простое включение
Пусть отсортировано начало массива A[1], A[2], ..., A[i-1], а остаток массива A[i], ...,A[n] содержит неотсортированную часть. На очередном шаге будем включать элемент A[i] в отсортированную часть, ставя его на соответствующее место. При этом придется сдвинуть часть элементов, больших A[i], (если таковые есть) на одну позицию правее, чтобы освободить место для элемента A[i]. Но при сдвиге будет потеряно само значение A[i], поскольку в эту позицию запишется первый (самый правый - с самым большим индексом) сдвигаемый элемент. Поэтому прежде чем производить сдвиг элементов необходимо сохранить значение A[i] в промежуточной переменной.
Так как массив из одного элемента можно считать отсортированным, начнем с i=2.
Программа будет выглядеть так:
for i := 2 to n do
begin
Tmp := A[i];
j := i-1;
while (A[j]>Tmp)and(j>1) do
begin
A[j+1] := A[j];
Dec(j)
end;
A[j+1] := Tmp;
end;
Этот алгоритм также имеет максимальную и среднюю сложности T(n2), но в случае исходно отсортированного массива внутренний цикл не будет выполняться ни разу, поэтому метод имеет Tmin(n). Можно заметить, что метод использует любой частичный порядок, и чем в большей степени массив исходно упорядочен, тем быстрее он закончит работу. В отличие от предыдущего метода, этот не требует дополнительной памяти.
2.2.3.2. Метод Шелла
Метод Шелла является усовершенствованием простого включения, которое основано на том, что включение использует любой частичный порядок. Но недостатком простого включения является то, что во внутреннем цикле элемент A[i] фактически сдвигается на одну позицию. И так до тех пор, пока он не достигнет своего места в отсортированной части. (На самом деле мы избавлялись от сдвига A[i], сохраняя его в промежуточной переменной, но сути метода это не изменяло, так как передвигалось место, оставленное под сохраненное значение). Метод Шелла позволяет преодолеть это ограничение следующим интересным способом.
Вместо включения A[i] в подмассив предшествующих ему элементов, его включают в подсписок, содержащий элементы A[i-h], A[i-2h], A[i-3h] и так далее, где h - положительная константа. Таким образом формируется массив, в котором «h- серии» элементов, отстоящих друг от друга на h, сортируются отдельно.
Конечно, этого недостаточно: процесс возобновляется с новым значением h, меньшим предыдущего. И так до тех пор, пока не будет достигнуто значение h=1.
В настоящее время неизвестна последовательность hi, hi-1, hi-2, ..., h1, оптимальность которой доказана. Для достаточно больших массивов рекомендуемой считается такая последовательность, что hi+1=3hi+1, а h1=1. Начинается процесс с hm-2, где m - наименьшее целое такое, что hmі n. Другими словами hm-2 первый такой член последовательности, что hm-2і [n/9].
Теперь запишем алгоритм:
Step := 1;
while Step < N div 9 do Step := Step*3 + 1;
Repeat
for k := 1 to Step do
begin
i := Step + k;
while i <= N do
begin
x := A^[i];
j := i - Step;
while (j >= 1) and (A^[j]>x) do
begin
A^[j + Step] := A^[j];
Dec(j);
end;
A^[j + Step] := x;
Inc(i, Step);
end;
end;
Step := Step div 3;
until Step=0;
Как показывают теоретические выкладки, которые мы приводить не будем, сортировке методом Шелла требуется в среднем 1,66n1,25 перемещений.
2.2.4. Сортировка извлечением
В этих методах массив также делится на уже отсортированную часть A[i+1], A[i+1], ..., A[n] и еще не отсортированную A[1], A[2], ..., A[i]. Но здесь из неотсортированной части на каждом шаге мы извлекаем максимальный элемент. Этот элемент будет минимальным элементом отсортированной части, так как все большие его элементы мы извлечем на предыдущих шагах, поэтому ставим извлеченный элемент в начало отсортированной части.
2.2.4.1. Простое извлечение
При простом извлечении мы будем искать максимальный элемент неотсортированной части, просматривая ее заново на каждом шаге. Найдя положение максимального элемента поменяем его с A[i] местами.
for i := N downto 2 do
begin
MaxIndex := 1;
for j := 2 to i do
if A[j]>A[MaxIndex] then
MaxIndex := j;
Tmp := A[i]; A[i] := A[MaxIndex];
A[MaxIndex] := Tmp;
end;
Простое извлечение во всех случаях имеет временную сложность T(n2) (два вложенных цикла, зависящих от n линейно).
2.2.4.2. Древесная сортировка
Древесная сортировка избегает необходимости каждый раз находить максимальный элемент. При следовании этому методу постоянно поддерживается такой порядок, при котором максимальный элемент всегда будет оказываться в A[1]. Сортировка называется древесной, потому что в этом методе используется структура данных, называемая двоичным деревом.
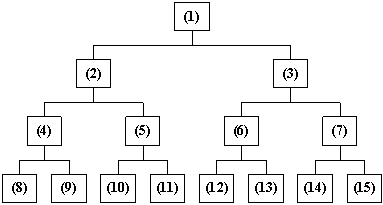
Двоичное дерево имеет элемент, называемый корнем. Корень, как и любой другой элемент дерева (называемый вершиной), может иметь до двух элементов-сыновей. Все элементы, кроме корневого имеют элемент-родитель.
Условимся нумеровать вершины числами 1, 2, ...: сыновьями вершины с номером k будут вершины с номерами 2*k и 2*k+1, - как это сделано на рисунке. Как можно заметить, двоичное разложение номера вершины указывает путь к этой вершине от корня (0 - к левому сыну, 1 - к правому сыну). Например, 910=10012. Первую 1 двоичного разложения пропускаем (в начале всегда стоит 1). Затем идет 0, то есть от корня переходим к левому сыну (вершина номер 210=102), потом снова 0 - переходим к левому сыну (вершина номер 410=1002), последней следует цифра 1 - переходим к правому сыну и как раз попадаем в вершину номер 910=10012. Значит номер элемента однозначно определяет его положение в дереве.
Введенный способ нумерации вершин дерева позволяет хранить деревья в массиве, где индекс массива будет номером вершины.
Пусть A[1]..A[n] - массив, подлежащий сортировке. Вершинами дерева будут числа от 1 до n; о числе A[i] мы будем говорить как о числе, стоящем в вершине i. В процессе сортировки количество вершин дерева будет сокращаться. Число вершин текущего дерева будем хранить в переменной k. Таким образом, в процессе работы алгоритма массив A[1]..A[n] делится на две части: в A[1]..A[k] хранятся числа на дереве, а в A[k+1] .. A[n] хранится уже отсортированная в порядке возрастания часть массива - элементы, уже занявшие свое законное место.
На каждом шаге алгоритм будет изымать максимальный элемент дерева и помещать его в отсортированную часть, на освободившееся в результате сокращения дерева место.
Договоримся о терминологии. Вершинами дерева считаются числа от 1 до текущего значения переменной k. У каждой вершины s могут быть сыновья 2*s и 2*s+1. Если оба этих числа больше k, то сыновей нет; такая вершина называется листом. Если 2*s=k, то вершина s имеет ровно одного сына (2*s).
Для каждого s из 1..k рассмотрим "поддерево" с корнем в s: оно содержит вершину s и всех ее потомков (сыновей, сыновей сыновей и т.д. - до тех пор, пока мы не выйдем из отрезка 1..k).
Вершину s будем называть регулярной, если стоящее в ней число - максимальный элемент s-поддерева; s-поддерево назовем регулярным, если все его вершины регулярны. (В частности, любой лист образует регулярное одноэлементное поддерево.)
Схема алгоритма такова:
k:= n
... Сделать 1-поддерево регулярным;
while k<>1 do
begin
... обменять местами A[1] и A[k];
k := k - 1;
{A[1]..A[k-1] <= A[k] <=...<= A[n];
1-поддерево регулярно везде, кроме, возможно,
самого корня }
... восстановить регулярность 1-поддерева всюду
end;
В качестве вспомогательной процедуры нам понадобится процедура восстановления регулярности s-поддерева в корне. Вот она:
{s-поддерево регулярно везде, кроме, возможно, корня}
t := s;
{s-поддерево регулярно везде, кроме, возможно,
вершины t}
while ((2*t+1<=k) and (A[2*t+1]>A[t])) or
((2*t<=k) and (A[2*t]>A[t])) do
begin
if (2*t+1<=k) and (A[2*t+1]>=A[2*t]) then
begin
... обменять A[t] и A[2*t+1];
t := 2*t + 1;
end else
begin
... обменять A[t] и A[2*t];
t := 2*t;
end;
end;
Чтобы убедиться в правильности этой процедуры, посмотрим на нее повнимательнее. Пусть в s-поддереве все вершины, кроме разве что вершины t, регулярны. Рассмотрим сыновей вершины t. Они регулярны, и потому содержат наибольшие числа в своих поддеревьях. Таким образом, на роль наибольшего числа в t-поддереве могут претендовать число в самой вершине t и числа, содержащиеся в ее сыновьях. (В первом случае вершина t регулярна, и все в порядке.) В этих терминах цикл можно записать так:
while наибольшее число не в t, а в одном из сыновей do
begin
if оно в правом сыне then
begin
...поменять t с ее правым сыном; t:= правый сын
end else
begin {наибольшее число - в левом сыне}
...поменять t с ее левым сыном; t:= левый сын
end
end
После обмена вершина t становится регулярной (в нее попадает максимальное число t-поддерева). Не принявший участия в обмене сын остается регулярным, а принявший участие может и не быть регулярным. В остальных вершинах s-поддерева не изменились ни числа, ни поддеревья их потомков (разве что два элемента поддерева переставились), так что регулярность не нарушилась.
Эта же процедура может использоваться для того, чтобы сделать 1-поддерево регулярным на начальной стадии сортировки:
k := n;
u := n;
{все s-поддеревья с s>u регулярны }
while u<>0 do
begin
{u-поддерево регулярно везде, кроме разве что корня}
... восстановить регулярность u-поддерева в корне;
u:=u-1;
end;
Теперь запишем процедуру сортировки на паскале:
procedure Sort;
Var u, k: Integer;
procedure Exchange(i, j: Integer);
Var Tmp: Integer;
begin
Tmp := x[i]; A[i] := A[j]; A[j] := Tmp;
end;
procedure Restore(s: Integer);
Var t: Integer;
begin
t:=s;
while ((2*t+1<=k) and (A[2*t+1]>A[t])) or
((2*t<=k) and (A[2*t]>A[t])) do
begin
if (2*t+1<=k) and (A[2*t+1]>=A[2*t]) then
begin
Exchange(t, 2*t+1);
t := 2*t+1;
end else
begin
Exchange(t, 2*t);
t := 2*t;
end;
end;
end;
begin
k:=n;
u:=n;
while u<>0 do
begin
Restore(u);
Dec(u);
end;
while k<>1 do
begin
Exchange(1, k);
Dec(k);
Restore(1);
end;
end;
Преимущество этого метода перед другими в том, что он, имея Tmax(n*log(n)) (внутри внешнего цикла зависящего от n линейно вызывается процедура Restore, требующая порядка log(n) действий), при сортировке не требует дополнительной памяти порядка n.
2.2.5. Сортировка обменами
Как следует из названия метода он сортирует массив путем последовательных обменов пар элементов местами.
2.2.5.1. Пузырьковая сортировка
Пузырьковая сортировка - один из наиболее широко известных алгоритмов сортировки. В этом методе массив также делится на две части: отсортированную и неотсортированную. На каждом шаге метода мы пробегаем от меньших индексов к большим по неотсортированной части, каждый раз сравнивая два соседних элемента: если они не упорядочены между собой (меньший следует за большим), то меняем их местами. Тем самым за один проход путем последовательных обменов наибольший элемент неотсортированной части сдвинется к ее концу.
Алгоритм называют пузырьковой сортировкой, потому что на каждом шаге наибольший элемент неотсортированной части подобно пузырьку газа в воде всплывает вверх.
Запишем алгоритм на языке Паскаль, заметив, что в том случае, когда за очередной проход не было сделано ни одного обмена, массив уже отсортирован и следующие проходы можно пропустить. Для отслеживания такой ситуации введем логическую переменную Flag - признак совершения обмена на очередном проходе:
for i := N-1 downto 1 do
begin
Flag := false;
for j := 1 to i do
if a[j]>a[j+1] then
begin
Tmp := A[j]; A[j] := A[j+1]; A[j+1] := Tmp;
Flag := true;
end;
if not Flag then Break;
end;
Этот алгоритм имеет среднюю и максимальную временные сложности T(n2) (два вложенных цикла, зависящих от n линейно) и не требует дополнительной памяти за исключением памяти для фиксированного числа переменных (i, j, Tmp, Flag). Введение переменной Flag и прерывание работы в случае отсортированного массива позволяет свести минимальную временную сложность к T(n).
2.2.5.2. Быстрая сортировка (Хоара)
Эту сортировку называют быстрой, потому что на практике она оказывается самым быстрым методом сортировки из тех, что оперируют сравнениями.
Этот метод является ярким примером реализации принципа «разделяй и властвуй». Как показывают теоретические выкладки наиболее эффективным в общем случае оказывается разделение задачи на две равные по сложности части, что мы и будем пытаться делать в этом методе.
На каждом шаге метода мы сначала выбираем «средний» элемент, затем переставляем элементы массива так, что он делится на три части: сначала следуют элементы, меньшие «среднего», потом равные ему, а в третьей части - большие. После такого деления массива остается только отсортировать первую и третью его части, с которыми мы поступим аналогично (разделим на три части). И так до тех пор, пока эти части не окажутся состоящими из одного элемента, а массив из одного элемента всегда отсортирован.
Запишем то, что мы сейчас сформулировали:
procedure Sort;
procedure QuickSort(a, b: Longint);
Var
x: Longint; {индекс «среднего» элемента}
begin
x := элемент_выбранный_средним;
...деление на три части:
1) A[a]..A[i]; 2) A[i+1]..A[j-1]; 3) A[j]..A[b]
if i>a then QuickSort(a, i);
if b>j then QuickSort(j, b);
end;
begin
Sort(1, N);
end;
Выбор «среднего» - задача непростая, так как требуется, не производя сортировку, найти элемент со значением максимально близким к среднему. Здесь, конечно, можно просто выбрать произвольный элемент (обычно выбирают элемент, стоящий в середине сортируемого подмассива), но пойдем чуть дальше: из трех элементов (самого левого, самого правого и стоящего посередине) выберем средний:
i := A[l]; y := A[(l+r)div 2]; j := A[r];
if i<=y then
if y<=j then
x := (l+r)div 2
else
if i<=j then
x := r
else
x := l
else
if y>=j then
x := (l+r)div 2
else
if i>=j then
x := r
else
x := l;
Теперь нам надо разделить массив относительно элемента A[x] так, чтобы сначала следовали элементы, меньшие A[x], затем сам элемент A[x], а потом уже элементы, большие или равные A[x]. Для этого мы, двигаясь слева найдем первый элемент A[i], больший A[x], и, двигаясь справа, - первый элемент A[j], меньший A[x]. Если i окажется меньше j, то это значит, что массив еще не поделен на три искомых части, в таком случае обменяем местами элементы A[i] и A[j], а затем продолжим поиск слева от A[i] и справа от A[j].
i := l; j := r; x := A[x];
repeat
while A[i] < x do Inc(I);
while x < A[j] do Dec(j);
if i <= j then
begin
y := A[i]; A[i] := A[j]; A[j] := y;
Inc(i); Dec(j);
end;
until i > j;
Пойдем дальше. Заметим, что все-таки наш способ нахождения «среднего» элемента подмассива в худшем случае приведет к тому, что после деления, например, правая и средняя части поделенного массива будут содержать по одному элементу, а левая все остальные. В этом случае, если мы сначала вызовем QuickSort для левой части, то (опять же в худшем случае) это может породить порядка N рекурсивных вызовов. А значит нам надо будет завести дополнительную память размером пропорциональным N и пространственная сложность будет O(N). Этого можно избежать, если сначала вызывать QuickSort для меньшей части. Тогда можно гарантировать пространственную сложность O(log(N)).
Теперь осталось только собрать вместе части программы:
procedure Sort;
procedure QuickSort(a, b: Longint);
Var
x: Longint; {индекс «среднего» элемента}
begin
i := A[l]; y := A[(l+r)div 2]; j := A[r];
if i<=y then
if y<=j then
x := (l+r)div 2
else
if i<=j then
x := r
else
x := l
else
if y>=j then
x := (l+r)div 2
else
if i>=j then
x := r
else
x := l;
i := l; j := r; x := A[x];
repeat
while A[i] < x do Inc(i);
while x < A[j] do Dec(j);
if i <= j then
begin
y := A[i]; A[i] := A[j]; A[j] := y;
Inc(i); Dec(j);
end;
until i > j;
if l-j<i-r then
begin
if l < j then QuickSort(l, j);
if i < r then QuickSort(i, r);
end else
begin
if i < r then Sort(i, r);
if l < j then Sort(l, j);
end;
end;
begin
QuickSort(1, N);
end;
В худшем случае этот алгоритм дает временную сложность Tmax(N2) (для случая, когда все выборки «среднего» элемента оказались неудачны), но как показывают теоретические исследования вероятность такого случая очень мала. В среднем же и в лучшем случае получим T(N*log(N)).
2.2.6. Сортировка слиянием
Этот метод сортирует массив последовательным слиянием пар уже отсортированных подмассивов, поэтому его и назвали сортировкой слиянием.
Пусть k - положительное целое число. Разобьем массив A[1]..A[n] на отрезки длины k. (Первый - A[1]..A[k], затем A[k+1]..A[2k] и т.д.) Последний отрезок будет неполным, если n не делится нацело на k. Назовем массив k-упорядоченным, если каждый из этих отрезков длины k упорядочен.
Ясно, что любой массив 1-упорядочен, так как его подмассивы длиной 1 можно считать упорядоченными. Если массив k-упорядочен и n<=k, то он упорядочен.
Теперь запишем общую схему алгоритма:
k:=1;
while k < n do
begin
... преобразовать k-упорядоченный массив
в 2k-упорядоченный;
k := 2 * k;
end;
Рассмотрим процедуру преобразования k-упорядоченного массива в 2k-упорядоченный. Сгруппируем все подмассивы длины k в пары подмассивов. Теперь пару упорядоченных подмассивов сольем в один упорядоченный подмассив. Проделав это со всеми парами, мы получим 2k-упорядоченный массив:
t:=0;
while t + k < n do
begin
p := t;
q := t+k;
...r := min(t+2*k, n); {в паскале нет функции min }
...сливаем два подмассива A[p..q-1] и A[q..r]
t := r;
end;
Слияние требует вспомогательного массива для записи результатов слияния - обозначим его B. Через p0 и q0 обозначим номера последних элементов участков, подвергшихся слиянию, s0 - последний записанный в массив B элемент. На каждом шаге слияния производится одно из двух действий:
B[s0+1]:=A[p0+1];
Inc(p0);
Inc(s0);
или
B[s0+1]:=A[q0+1];
Inc(q0);
Inc(s0);
Первое действие (взятие элемента из первого отрезка) может производиться при двух условиях:
(1) первый отрезок не кончился (p0 < q);
(2) второй отрезок кончился (q0 = r) или не кончился, но элемент в нем не меньше [(q0 < r) и (A[p0+1] <= A[q0+1])].
Аналогично для второго действия. Итак, получаем
p0 := p; q0 := q; s0 := p;
while (p0<>q)or(q0<>r) do
begin
if (p0<q)and((q0=r)or((q0 < r) and
(A[p0+1]<=A[q0+1]))) then
begin
B[s0+1] := A[p0+1]; Inc(p0); Inc(s0);
end else
begin
B[s0+1] := A[q0+1]; Inc(q0); Inc(s0);
end;
end;
(Если оба отрезка не кончены и первые невыбранные элементы в них равны, то допустимы оба действия; в программе выбрано первое.)
Осталось собрать программу в одно целое:
k := 1;
while k < N do
begin
t := 0;
while t+k < N do
begin
p := t; q := t+k;
if t+2*k>N then r := N else r := t+2*k;
p0 := p; q0 := q; s0 := p;
while (p0<>q) or (q0<>r) do
begin
if (p0<q) and ((q0=r)or((q0<r)and
(A[p0+1]<=A[q0+1]))) then
begin
B[s0+1] := A[p0+1];
Inc(p0);
end else
begin
B[s0+1] := A[q0+1];
Inc(q0);
end;
Inc(s0);
end;
t := r;
end;
k := k shl 1;
A := B;
end;
Сразу же бросается в глаза недостаток метода – он требует дополнительную память размером порядка N (для хранения вспомогательного массива). Но как и для древесной сортировки, его временная сложность всегда пропорциональна N*log(N) (так как преобразование k-упорядоченного массива в 2k-упорядоченный требует порядка N действий и внешний цикл по k совершает порядка log(N) итераций).
2.2.7. Сортировка распределением
Сортировка распределением интересна тем, что она сортирует массив, не сравнивая элементы друг с другом.
Рассмотрим сначала вырожденный случай сортировки распределением, а затем более общий.
2.2.7.1. Вырожденное распределение
Пусть каждый элемент массива может принимать M (например, от 1 до M) фиксированных значений. Заведем массив Amount, первоначально обнулив его. Затем для каждого i подсчитаем количество элементов массива A, равных i, и занесем это число в Amount[i]:
for i := 0 to M do Amount[i] := 0;
for i := 1 to N do
Inc(Amount[A[i]]);
Теперь в первые Amount[1] элементов массива A запишем 1, в следующие Amount[2] элементов массива A запишем 2 и т.д. до тех пор, пока не дойдем до конца массива A (заметим, что в то же время мы окажемся в конце массива Amount):
p := 1;
for i := 0 to M do
for j := 1 to Amount[i] do
begin
A[p] := i;
Inc(p);
end;
Несмотря на то, что здесь два внешних цикла на этом участке алгоритма выполняется порядка N действий. Это следует из того, что 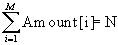 . Поэтому временную сложность метода можно оценить как T(M+N) (M появляется в сумме, так как изначально надо обнулить массив Amount, а это требует M действий). Пространственная сложность в этом случае равна O(M), поскольку требуется дополнительная память размером порядка M.
. Поэтому временную сложность метода можно оценить как T(M+N) (M появляется в сумме, так как изначально надо обнулить массив Amount, а это требует M действий). Пространственная сложность в этом случае равна O(M), поскольку требуется дополнительная память размером порядка M.
Недостатком этого метода является то, что требуется дополнительная память размером порядка M, а это может оказаться недопустимым из-за большого значения M. Но, если M>>N, то есть способ уменьшить объем требуемой дополнительной памяти, который мы сейчас и рассмотрим.
2.2.7.2. Сортировка распределением
Пусть мы можем завести дополнительную память размером M+N, а элементы массива могут принимать значения от 0 до S, причем S>>M.
Каждый элемент этого массива можно представить в M-ичной системе счисления и разбить на K цифр этой системы счисления.
Заведем M списков общей суммарной длиной порядка N (это можно сделать, ограничившись дополнительной памятью O(M+N)).
Наш алгоритм можно представить следующим образом:
for i := K downto 1 do
begin
for j := 1 to N do
begin
L:=<i-ой цифре A[j] в M-ной системе счисления>;
... занести A[j] в L-ный список;
end;
... очистить массив A
for j := 1 to M do
... дописать элементы j-ого списка в массив A
end;
Итак, как видно из приведенной выше программы, на каждом шаге метода производится сортировка элементов массива по значению i-ого разряда. При этом производится промежуточное распределение элементов массива по спискам в зависимости от значения соответствующего разряда этих элементов. Во время распределения очень важно сохранить при записи в списки порядок следования элементов, чтобы не нарушить порядок, достигнутый на предыдущих шагах.
Индукцией по i легко доказать, что после i шагов любые два числа, отличающиеся только в i последних разрядах, идут в правильном порядке.
Достигнув i=1, мы получим полностью отсортированный массив.
Как нетрудно заметить, если положить S=M, то отпадает необходимость заводить списки и производить запись в них: в j–ый список будут попадать только числа, равные j. В этом случае достаточно хранить лишь размеры списков, то есть подсчитать количество элементов, равных j, для всех j от 1 до S. А потом просто заново заполнить массив A в соответствии с этими количествами. Что мы и делали в случае вырожденной сортировки.
Интересно, что временная сложность этого метода T(K*N), а если учесть, что K фактически является константой, то мы получаем гарантированную (минимальную, среднюю и максимальную) линейную сложность. Но недостатком этого метода является необходимость выделять дополнительную память размером порядка M+N. Если бы не это ограничение, можно было бы считать этот метод самым эффективным при больших значениях N.
2.3. Сравнительный анализ
Для проведения экспериментального сравнительного анализа различных методов сортировки была разработана программа, которая в автоматическом режиме подсчитывала время, требуемое для каждого метода сортировки. Для чистоты эксперимента сортировка всеми методами проводилась на одинаковых наборах входных данных, затем формировался новый набор данных, и они опять подвергались сортировке различными методами. Таким образом было выполнено 60 циклов сортировки, подсчитано среднее время, которое потребовалось каждому методу, чтобы отсортировать входной массив. Для более полного анализа методов в каждом цикле сортировки сортировка проводилась для размерностей 500, 1000, 3000, 5000, 8000, 10000, 30000, 60000. Это дало возможность проследить динамику роста требуемого для сортировки времени. Также проверялось, как ведут себя методы на различных входных данных: упорядоченных в прямом порядке, упорядоченных в обратном порядке и случайных.
Ниже приведены таблицы, которые выдала составленная программа.
а) Для массива, заполненного случайными элементами:
|
|
500 |
1000 |
3000 |
5000 |
8000 |
10000 |
30000 |
60000 |
|
Подсчетом |
0.08 |
0.31 |
2.76 |
7.67 |
19.67 |
|
|
|
|
Включением |
0.03 |
0.06 |
0.60 |
1.66 |
4.22 |
6.58 |
59.62 |
|
|
Шелла |
0.02 |
0.05 |
0.43 |
1.12 |
2.72 |
4.24 |
35.62 |
|
|
Слиянием |
0.03 |
0.02 |
0.06 |
0.09 |
0.11 |
0.13 |
0.38 |
0.77 |
|
Извлечением |
0.01 |
0.10 |
0.92 |
2.54 |
6.51 |
10.17 |
|
|
|
Древесная |
0.02 |
0.02 |
0.11 |
0.20 |
0.33 |
0.42 |
1.39 |
3.02 |
|
Пузырьковая |
0.07 |
0.27 |
2.43 |
6.75 |
17.28 |
|
|
|
|
Быстрая |
0.00 |
0.00 |
0.01 |
0.03 |
0.03 |
0.04 |
0.13 |
0.27 |
|
Двоичным |
0.00 |
0.00 |
0.02 |
0.03 |
0.05 |
0.06 |
0.20 |
0.38 |
|
Вырожденным распределением |
0.00 |
0.00 |
0.00 |
0.00 |
0.01 |
0.01 |
0.01 |
0.02 |
б) Для исходно упорядоченного массива:
|
|
500 |
1000 |
3000 |
5000 |
8000 |
10000 |
30000 |
60000 |
|
Подсчетом |
0.08 |
0.32 |
2.65 |
7.26 |
18.46 |
|
|
|
|
Включением |
0.00 |
0.00 |
0.00 |
0.00 |
0.01 |
0.01 |
0.01 |
0.03 |
|
Шелла |
0.00 |
0.00 |
0.01 |
0.02 |
0.02 |
0.05 |
0.15 |
0.29 |
|
Слиянием |
0.02 |
0.02 |
0.04 |
0.08 |
0.09 |
0.12 |
0.31 |
0.63 |
|
Извлечением |
0.02 |
0.11 |
0.92 |
2.54 |
6.53 |
10.20 |
|
|
|
Древесная |
0.01 |
0.03 |
0.11 |
0.19 |
0.34 |
0.43 |
1.45 |
3.11 |
|
Пузырьковая |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
0.01 |
0.01 |
0.02 |
|
Быстрая |
0.00 |
0.00 |
0.01 |
0.02 |
0.03 |
0.04 |
0.11 |
0.22 |
|
Двоичным |
0.00 |
0.01 |
0.02 |
0.03 |
0.04 |
0.05 |
0.18 |
0.36 |
|
Вырожденным распределением |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
0.01 |
0.01 |
0.02 |
в) Для массива исходно упорядоченного в обратном порядке:
|
|
500 |
1000 |
3000 |
5000 |
8000 |
10000 |
30000 |
60000 |
|
Подсчетом |
0.09 |
0.32 |
2.64 |
7.26 |
18.47 |
|
|
|
|
Включением |
0.02 |
0.13 |
1.16 |
3.26 |
8.37 |
13.08 |
|
|
|
Шелла |
0.01 |
0.00 |
0.03 |
0.16 |
0.21 |
0.27 |
2.09 |
8.02 |
|
Слиянием |
0.02 |
0.03 |
0.06 |
0.06 |
0.10 |
0.11 |
0.32 |
0.64 |
|
Извлечением |
0.02 |
0.11 |
0.91 |
2.54 |
6.51 |
10.19 |
|
|
|
Древесная |
0.00 |
0.02 |
0.10 |
0.18 |
0.30 |
0.39 |
1.32 |
2.85 |
|
Пузырьковая |
0.06 |
0.29 |
2.95 |
8.35 |
21.60 |
|
|
|
|
Быстрая |
0.00 |
0.00 |
0.01 |
0.01 |
0.03 |
0.04 |
0.11 |
0.24 |
|
Двоичным |
0.01 |
0.01 |
0.03 |
0.03 |
0.05 |
0.07 |
0.19 |
0.37 |
|
Вырожденным распределением |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
0.01 |
0.03 |
Примечание. Пусты ячейки, для которых испытание не проводилось. Время засекалось с точностью до одной пятидесятой секунды, поэтому нули в таблице означают, что было затрачено меньше времени, чем одна пятидесятая доля секунды. Испытание проводилось на AMD-K5-PR133/32Mb EDO/850Mb под управлением MS-DOS 7.0, входящую в состав WINDOWS 95. Массивы размещались в динамической памяти.
Теоретические сложности рассмотренных методов сортировки:
|
|
Tmax |
Tmid |
Tmin |
Omax |
|
Подсчетом |
n2 |
n |
||
|
Включением |
n2 |
n |
1 |
|
|
Шелла |
n2 |
n1,25 |
n |
1 |
|
Извлечением |
n2 |
1 |
||
|
Древесная |
n*log(n) |
1 |
||
|
Пузырьковая |
n2 |
n |
1 |
|
|
Быстрая |
n2 |
n*log(n) |
log(n) |
|
|
Слиянием |
n*log(n) |
n |
||
|
Распределением |
n |
n |
||
Эти таблицы позволяют сделать ряд выводов.
- На небольших наборах данных целесообразнее использовать сортировку включением, так как из всех методов, имеющих очень простую программную реализацию, этот на практике оказывается самым быстрым и при размерностях<~3000 дает вполне приемлемую для большинства случаев скорость работы. Еще одно преимущество этого метода заключается в том, что он использует полную или частичную упорядоченность входных данных и на упорядоченных данных работает быстрее, а на практике данные, как правило, уже имеют хотя бы частичный порядок.
- Алгоритм пузырьковой сортировки, причем в той его модификации, которая не использует частичный порядок данных исходного массива, хотя и часто используется, но имеет плохие показатели даже среди простых методов с квадратичной сложностью.
- Сортировка Шелла оказывается лишь красивым теоретическим методом, потому что на практике использовать его нецелесообразно: он сложен в реализации, но не дает такой скорости, какую дают сравнимые с ним по сложности программной реализации методы.
- При сортировке больших массивов исходных данных лучше использовать быструю сортировку.
- Если же добавляется требование гарантировать приемлемое время работы метода (как вы помните, быстрая сортировка в худшем случае имеет сложность T(N2), хотя вероятность такого случая очень мала), то надо применять либо древесную сортировку, либо сортировку слиянием. Как видно из таблиц, сортировка слиянием работает быстрее, но следует помнить, что она требует дополнительную память размером порядка N.
- В тех же случаях, когда мы можем себе позволить использовать дополнительную память размером порядка n, имеет смысл воспользоваться сортировкой распределением.
3. Контрольные вопросы
- Что такое сортировка? Чем отличаются внешняя и внутренняя сортировка?
- Что такое практическая и теоретическая сложности? Можно ли из практической сложности вывести теоретическую? Можно ли из теоретической сложности вывести практическую?
- Что такое максимальная, средняя и минимальная сложности?
- Что означает T(1)?
- Общее в методах сортировки включением (сортировки включением и метода Шелла)?
- Доказать, что метод Шелла действительно сортирует массив.
- Общее в методах сортировки извлечением (сортировки извлечением и древесная)?
- Описать способ хранения двоичного дерева, используемый в древесной сортировке.
- Что такое регулярная вершина дерева? регулярное поддерево?
- Доказать, что древесная сортировка действительно сортирует массив.
- Почему нельзя сделать так, чтобы быстрая сортировка давала гарантированную сложность T(n*log(n))? (Подсказка: причина в алгоритме выбора среднего элемента)
- Как мы можем гарантировать пространственную сложность O(log(n)) при реализации метода быстрой сортировки?
- Доказать, что сортировка слиянием действительно сортирует массив.
- Доказать, что сортировка распределением действительно сортирует массив.
4. Методические указания.
Перед выполнением индивидуального задания ознакомиться с понятиями временной и пространственной сложности, методами сортировки, их сравнительным анализом.
При выполнении индивидуального задания придерживаться следующей последовательности действий:
- изучить словесную постановку задачи;
- выбрать метод сортировки, который лучше всего подходит для решения поставленной задачи;
- разработать программу, решающую поставленную задачу;
- оттестировать и отладить программу;
- написать и представить к защите отчет по работе.
5. Содержание отчета
- Титульный лист.
- Словесная постановка задачи.
- Алгоритм решения задачи в текстуальном виде.
- Обоснование правильности работы алгоритма и правильности выбора метода сортировки исходя из постановки задачи.
- Листинг программы.
- Ответы на контрольные вопросы по согласованию с преподавателем.
6. Варианты индивидуальных заданий
Сортировка имеет множество практических применений: прямых, когда прямо ставится задача отсортировать данные; и косвенных, когда при решении какой-либо задачи требуется промежуточная сортировка данных. Здесь будут приведены ряд задач, при решении которых удобно использовать сортировку.
Во всех задачах надо обязательно показать, почему Ваш алгоритм обеспечивает заданную временную сложность.
Задача 1. Найти количество различных чисел среди элементов данного массива. Обеспечить число действий порядка n*log n.
Указание. Отсортировать числа, а затем посчитать количество различных, просматривая элементы массива по порядку.
Задача 2. Найти k-ое по порядку число среди элементов данного массива. Обеспечить число действий порядка n*log n.
Указание. Отсортировать массив, а затем взять число, хранящееся в элементе массива с индексом k.
Задача 3. Дано n отрезков [A[i], B[i]] на прямой (i=1..n), где A[i] – одномерная координата начала отрезка, а B[i] – конца отрезка.
Найти максимальное k, для которого существует точка прямой, покрытая k отрезками ("максимальное число слоев"). Обеспечить число действий - порядка n*log n.
Указание. Упорядочим все левые и правые концы отрезков вместе (при этом левый конец считается меньше правого конца, расположенного в той же точке прямой). Далее двигаемся слева направо, считая число слоев. Встреченный левый конец увеличивает число слоев на 1, правый - уменьшает. Отметим, что примыкающие друг к другу отрезки обрабатываются правильно: сначала идет левый конец (правого отрезка), а затем - правый (левого отрезка).
Задача 4. Дано n точек на плоскости. Указать (n-1)-звенную несамопересекающуюся незамкнутую ломаную, проходящую через все эти точки. (Соседним отрезкам ломаной разрешается лежать на одной прямой.) Обеспечить число действий порядка n*log n.
Указание. Упорядочим точки по x-координате, а при равных x-координатах - по y-координате. В таком порядке и можно проводить ломаную.
Задача 5. Та же задача, если ломаная должна быть замкнутой.
Указание. Возьмем самую левую точку (т.е. точку с наименьшей x-координатой) и проведем из нее лучи во все остальные точки. Теперь упорядочим эти лучи, а точки на одном луче поместим в порядке увеличения расстояния от начала луча.
Задача 6. Дано n точек на плоскости. Построить их выпуклую оболочку - минимальную выпуклую фигуру, их содержащую. (Форму выпуклой оболочки примет резиновое колечко, если его натянуть на гвозди, вбитые в точках.) Обеспечить число операций порядка n*log n.
Указание. Упорядочим точки - годится любой из порядков, использованных в двух предыдущих задачах. Затем, рассматривая точки по очереди, будем строить выпуклую оболочку уже рассмотренных точек. (Для хранения выпуклой оболочки полезно использовать дек – смотрите главу «Стеки, очереди, деки»)
Задача 7. Дан массив, состоящий из чисел 0, 1 и 2. Переместить все 0 в начало массива, а 2 – в конец. Обеспечить число действий порядка n.
Указание. Воспользоваться вырожденной сортировкой распределением.
Задача 8. В неупорядоченном массиве А могут быть совпадающие элементы. Из каждой группы одинаковых элементов оставить только один, удалив остальные и «поджав» массив к его началу. Обеспечить число операций порядка n*log n.
Указание. Можно сначала отсортировать массив, а затем произвести его «поджатие» с удалением повторяющихся. При удалении очередного повтора не надо сразу сдвигать весь массив (это может привести к сложности T(n2)) – достаточно, рассматривая массив поэлементно и помня последний рассмотренный элемент, либо пропускать очередной, либо приписывать его к уже просмотренной части.
Задача 9. Турнирная таблица соревнований представлена квадратной матрицей A, каждый элемент которой aij есть число голов, забитых i-ой командой в ворота j-ой команды. По диагонали расположить место каждой команды (по числу побед за вычетом числа поражений; в случае равенства – по разности забитых и пропущенных голов).
Задача 10. В целочисленном массиве найти наибольшее число одинаковых элементов.
Указание. Удобно предварительно отсортировать массив.
Задача 11. Отсортировать список по неубыванию. Гарантировать число действий порядка n. Элементы списка могут содержать числа от 1 до 1000000000.
Указание. Воспользоваться сортировкой распределением.