Testing suite in developing
Introduction, requirements
In this article I will consider a projected testing system that allows checking different human skills. Modern level of education and information technologies progression makes this problem a critical issue. The solution approach has to satisfy the following requirements (I will not include very obvious ones such as easy-to-use and etc. but only specific requirements):
- universality in the testing;
- providing ability to create new tests;
- supplying multiple-choice questions and self-typing questions;
- providing different test options (e.g., time limitation);
- supplying non-textual information;
- automatic generating of individual test tasks of equal maximum grade;
- designing software as a multi-tiered application with easy-to-maintain client-side part;
- storing full results information in a database (including questions asked and answers given by the tested person);
- representation of such objects as questions, tests in the virtual directories;
- user access restriction to virtual directories.
Consider some of these requirements and possible solutions.
Multiple-choice questions and self-typing questions
Multiple-choice questions don't cause any real difficulties. We should only solve the problem of storing this information. But we will not consider this here.
When we talk about self-typing question we must first of all define precisely how we will distinguish between right and wrong answers. Direct string comparing is not a good solution. For example, a user could type an additional space character and it will make his answer wrong. But at present we don't aim to recognise the natural language as an input string. It will be quite hard to configure such a system for a particular test. It will be difficult to implement such system. Really it is not needed in this particular case.
So it will be enough to design the right-answer-description-language based on regular expressions.
Here is concise definition of the right-answer-description-language.
- quoted sequence of symbols;
- set of characters inside of squared brackets;
- A+B (concatenation), where A and B are regular expressions;
- A|B (selection), where A and B are regular expressions;
- (A) (brackets can change usual precedence: first +, then |), where A and B are regular expressions;
- {A} (iteration), where A is regular expression.
Here is simple example:
Target = {æ Æ}+æ32Æ+{æ Æ}
Identifier Target has special meaning. It describes what is actually right answer and can use identifiers defined before. This example describes string '32' with any number of space characters before and after.
Here is another more complicated example:
Digit = [0-9]
Number = (æ-Æ|æ+Æ|æÆ)+Digit+{Digit}
Target = {æ Æ}+Number+{æ Æ}
Identifier Digit describes one digit from 0 to 9. Next identifier Number describes representation of integer number using identifier Digit defined before. And Target recognises number with any number of space characters before and after.
Supplying non-textual information representation
There are 2 different approaches for combining textual and non-textual information in one document.
First approach store non-textual and textual information in structured storage. It means that all information is stored in one file. The most known example is OLE compound document technology included in Windows OS.
Another approach keeps textual and non-textual information in different files. Everybody knows such example of this approach as HTML.
It is not reasonable to develop our own technology for representation of compound documents when there are solutions that have been already implemented and rather powerful.
Consider more significant advantages and disadvantages.
| OLE compound documents |
HTML-alike |
| You can edit all information any time, if appropriate software installed | Editing of non-textual information is usually hard or inconvenient because it is usually converted into images |
| Documents are available only on Windows | Cross-platform support |
All the same time we have to think of development tools and what they allow to do.
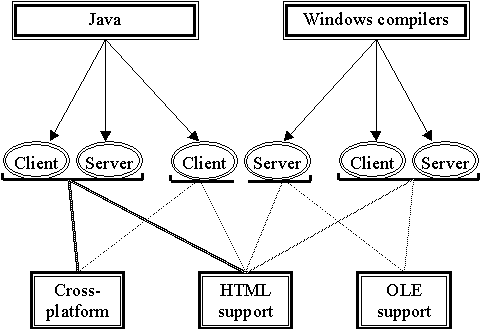
Here we can see how development tools influence to solutions and, contrary, solutions influence to development tools.
This software consists of client and server parts. We can implement some parts with Java and windows compilers. I donÆt consider another abilities because they donÆt add any power.
After considering these possible implementations I have chosen first one. You could ask me "Why?". First of all, because another ways use Windows compilers that makes them quite expensive. The most powerful Windows development suite for this particular task is the Delphi client/server version. Delphi has all needed components for rapid development multi-tiered applications including very powerful Internet components. In addition to said before there is Delphi component that supports rich text with OLE file format. (Usually development tools support only rich text format without OLE)
If I would have enough financial support I would prefer mixed solution. So that it could be possible to create tests by both OLE compound documents and HTML ways. I would create OLE to HTML converter in order to use it before sending information to Java-based testing client. It could make testing client platform independent.
So I have chosen Java as development tool and HTML as a way to work with mixed textual and non-textual documents.
Automatic generating of individual test tasks
Rules of generating individual tasks describe how software should create individual test task.
In fact, test is defined by rules of generating individual tasks. The main aim here is to provide creating tasks of equal grade on different computers.
We can do it by the next way.
- Divide questions into levels of difficulty so that all questions in same level have same maximal grade.
- Define precisely how many questions have to be given from every level of difficulty.
- Take so many questions from every level of difficulty as it was defined on step 2.
Steps 1 & 2 describe what test creator has to do. Step 3 describes what generating system is to do.
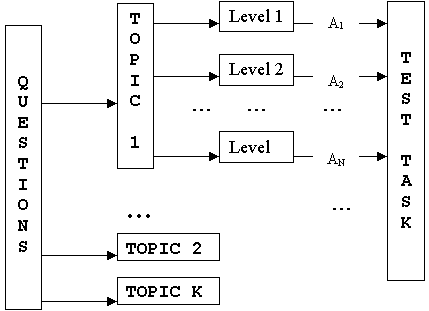
It is obvious that such algorithm will create test tasks of equal grade. This way of generating has yet another advantage. Subjects and topics could divide all questions into groups. For every group you can allocate several levels for arranging question of group by difficulty. It will assure that fixed number of questions of equal grade will be included into every individual test task.
Let us to notice that than more ratio total questions to given questions for every group than less probability of generating absolutely equal tasks.
The ideal situation is when base of questions holds not less than 500 items. In this case questions and answers could be published. It will allow everybody to familiarise with questions but it will be impossible to remember answers without understanding of topic. Such open system is very good for examinations.
Virtual directories
We will organise such objects as tests and questions so that it will look for user as stored in virtual directories. This way allows solving following problems:
- hierarchical arranging of information;
- user access restriction based on restriction access to directories;
- familiar way of storing big amounts of information (it is similar to storing files in directories).
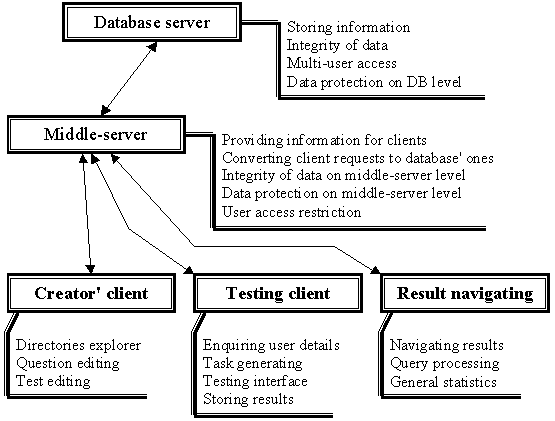
Software structure
As it was said before software is designed as multi-tiered application. So it will include database server, middle-server and several specific clients. There are clients for test creator, for testing and for result database navigating.